


 L’architecture de type CQRS (Command Query Responsibility Segregation) provient du mouvement DDD (Domain-driven design), en français Conception Pilotée par le Domaine. Le grand gourou du DDD est Eric Evans, auteur du livre « Domain-Driven Design: Tackling Complexity in the Heart of Software ».
L’architecture de type CQRS (Command Query Responsibility Segregation) provient du mouvement DDD (Domain-driven design), en français Conception Pilotée par le Domaine. Le grand gourou du DDD est Eric Evans, auteur du livre « Domain-Driven Design: Tackling Complexity in the Heart of Software ».
Le mouvement DDD promeut, au cœur de la conception logicielle, la modélisation des objets du domaine et l’expression des besoins via l’utilisation d’un langage dénommé « Ubiquitous Language ».
L’architecture CQRS propose la séparation au sein de votre application des composants qui font des écritures et de ceux qui ne font que de la lecture. Le paradigme sous jacent étant d’avoir une haute performance sur la partie « lecture ». Cette performance est obtenue au prix d’une dénormalisation au niveau des données en lecture seule.
La mise en place d’une architecture de type CQRS impose donc cette séparation physique comme le montre le schéma suivant :
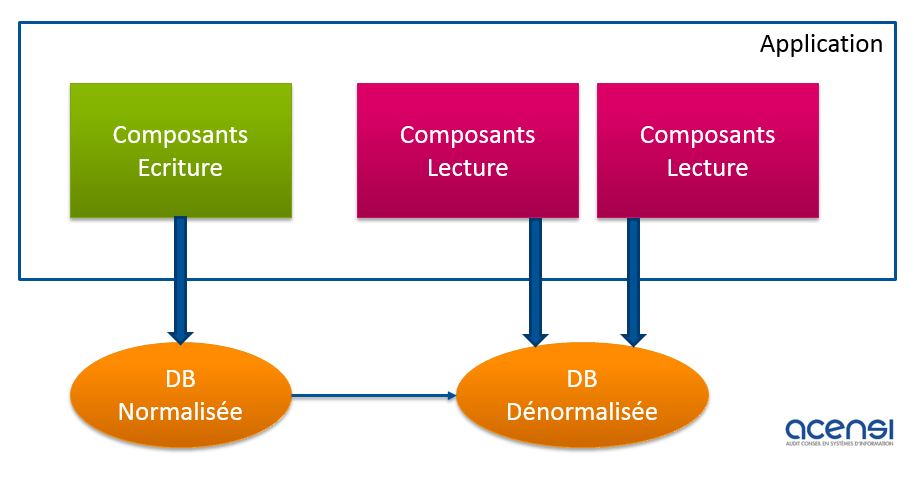
Ce schéma montre la capacité de mettre en place une scalabilité horizontale au niveau des composants de lecture, ce qui permet d’adresser les problématiques de performance et de résilience au niveau lecture.
Au niveau macro, les méthodes principales des composants d’écriture sont : « create, update, delete ». La méthode principale du contrat de lecture étant « read ».
Au niveau du composant d’écriture, toutes les problématiques transactionnelles doivent être adressées, c’est-à-dire que les principes ACID (atomicité, consistance, isolation, durabilité) doivent être respectés.
Pour que les données en lecture puissent être en phase avec les données en écriture, il faut un mécanisme de synchronisation.
Plusieurs techniques peuvent être utilisées. Dans cet article nous allons présenter « l’event sourcing » : une technique pour adresser cette problématique de données en écriture synchronisée avec les données en lecture.
L’event sourcing est donc une sorte de journal de log. On garde toute trace d’évènements apparus dans le système. Ce qui permet de reproduire un état passé consistant du système.
Le principe fondamental étant que chaque traitement engendrant une écriture dans le système soit transformé en événement. Les événements arrivent dans le passé (ex. le client A a changé d’adresse) et ils sont immutables. En mettant en place un système de dispatching des événements (un bus command handler), on peut adresser en même temps la partie « write » et la partie « read », comme le montre le schéma suivant :
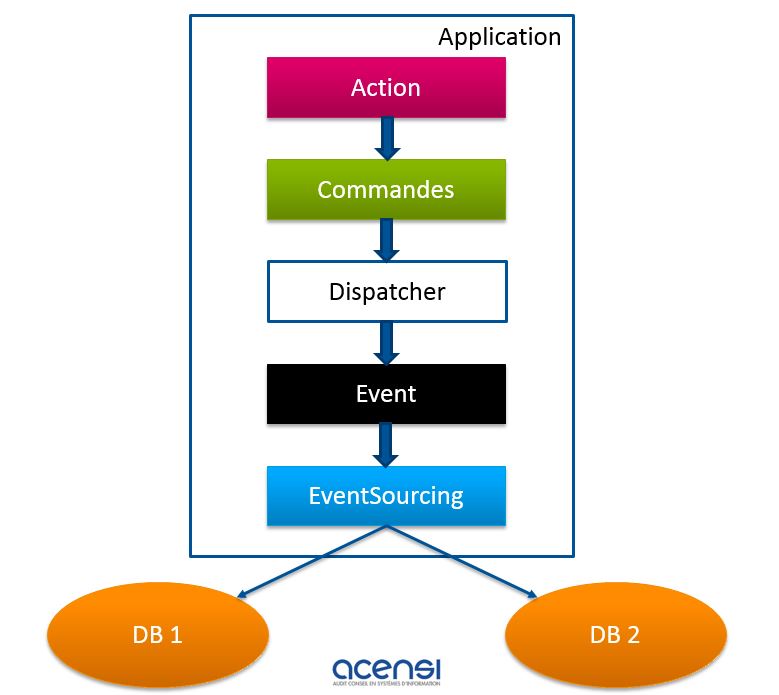
Décortiquons ce schéma.
Pour adresser la partie « write », il est recommandé d’utiliser le design pattern « command », ce qui permet d’exprimer clairement une intention plutôt qu’un changement basique. Un exemple pour illustrer ce propos est :
Supposons que dans une application de gestion de commande, on veut modifier l’adresse d’un client. On peut simplement ajouter dans le service d’écriture, une méthode « ChangeAddress(NewAdress) ». L’inconvénient de cette approche est qu’on ne sait pas ce qui a entrainé la modification de l’adresse : soit une erreur de saisie, soit un déménagement. Il faut donc faire un design du type :
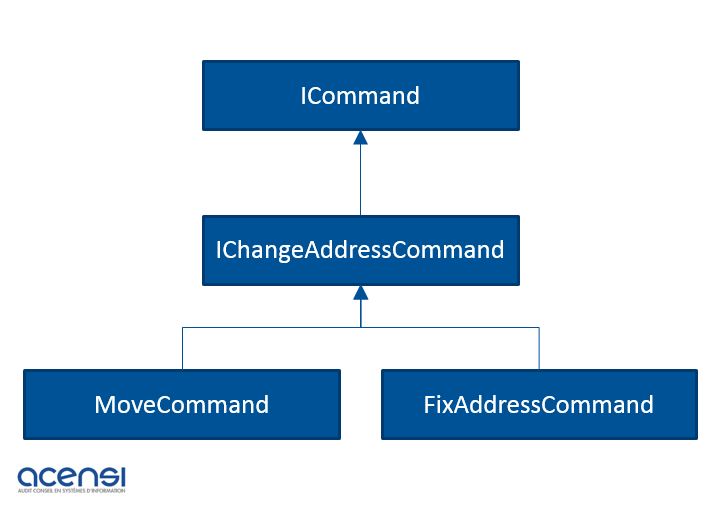
La commande est donc auto descriptive et contient clairement l’intention de la modification de l’adresse.
La commande est sérialisée et envoyée au bus de traitement des commandes qui est résilient aux pannes. On peut retourner au client que sa commande est prise en compte, ce qui permet une plus grande réactivité dans la partie write. Il est important de noter ici qu’aucune action en base n’est encore faite.
Un handler de commande récupère le message du bus et le transforme en événement.
Qu’est ce que l’événement a de plus que la commande ? On peut rajouter ici la date et l’heure de l’événement, l’utilisateur qui a initié la commande… C’est à dire des informations de décoration de la commande pour avoir un événement qui contient le maximum d’informations nécessaires au système.
L’événement enrichi est donc envoyé au gestionnaire des événements qui est tolérant aux pannes :
- On stocke l’événement dans un journal contenant tous les événements. C’est l’event sourcing
- On écrit dans la BD normalisée en utilisant par exemple un ORM en conjonction avec le pattern repository. On peut notifier ici (par exemple par mail) que sa commande est bien prise en compte et porte un identifiant donné.
- On écrit en général de manière asynchrone (pour plus de souplesse et de performance) dans la BD dénormalisée (par exemple un cache distribué) pour les clients en consultation.
Les lectures dans la BD en lecture peuvent être faites directement avec des protocoles plus bas niveau au lieu d’utiliser un ORM (JDBC, ADO.NET…) car ici on veut écrire directement des requêtes SQL optimisées. Si c’est un cache distribué, on accèdera directement au cache.
L’event store nous permet donc un stockage et une reproduction de tous les changements d’états du système (peut servir au Debug, à l’audit, aux tests de non régression…). Il contient plus d’informations métiers que le journal de log de la base de données. Ce n’est donc pas une redondance avec le redo log des bases de données relationnelles.
Comme mentionné au début de cet article, voici quelques liens pour aller plus loin concernant ce sujet :
- DDD, Eric Evans: Domain-Driven Design: Tackling Complexity in the Heart of Software
- CQRS Document, Greg Young: https://cqrs.files.wordpress.com/2010/11/cqrs_documents.pdf
- CQRS : http://cqrs.nu/
- CQRS, Martin Fowler: http://martinfowler.com/bliki/CQRS.html
- CQRS and Event sourcing: https://msdn.microsoft.com/fr-fr/library/dn568103.aspx
- Event sourcing, Martin Flowler: http://martinfowler.com/eaaDev/EventSourcing.html
- Introducing Event Sourcing: https://msdn.microsoft.com/en-us/library/jj591559.aspx
Adina & James












